I thought I’d share the Elasticsearch type mapping I am using for WordPress posts. We’ve refined it over a number of iterations and it combines dynamic templates and multi_field mappings along with a number of more standard mappings. So this is probably a good general example of how to index real data from a traditional SQL database into Elasticsearch.
If you aren’t familiar with the WordPress database scheme it looks like this:
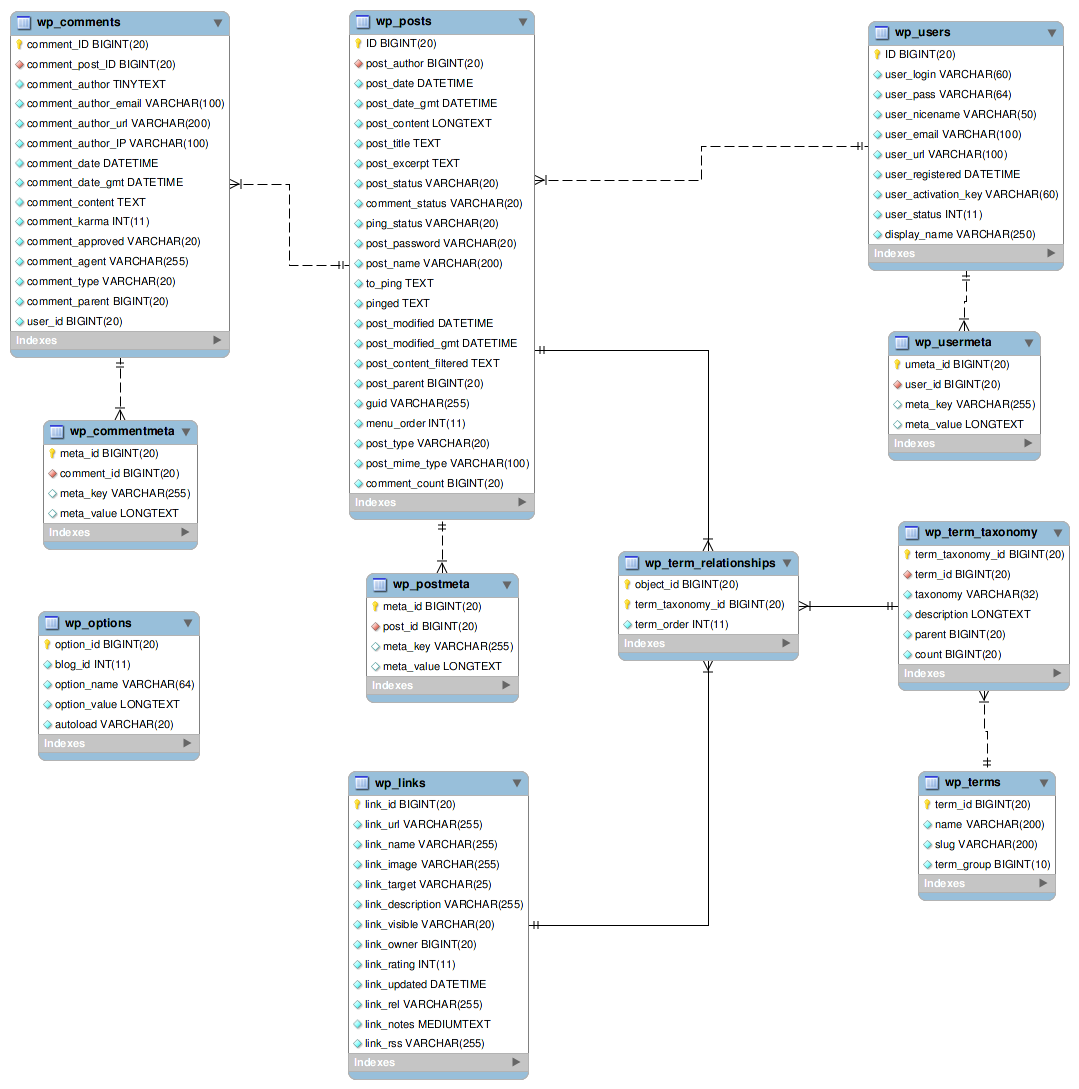
These Elasticsearch mappings focus on the wp_posts, wp_term_relationships, wp_term_taxonomy, and wp_terms tables.
To simplify things I’ll just index using an English analyzer and leave discussing multi-lingual analyzers to a different post.
"analysis": {
"filter": {
"stop_filter": {
"type": "stop",
"stopwords": ["_english_"]
},
"stemmer_filter": {
"type": "stemmer",
"name": "minimal_english"
}
},
"analyzer": {
"wp_analyzer": {
"type": "custom",
"tokenizer": "uax_url_email",
"filter": ["lowercase", "stop_filter", "stemmer_filter"],
"char_filter": ["html_strip"]
},
"wp_raw_lowercase_analyzer": {
"type": "custom",
"tokenizer": "keyword",
"filter": ["lowercase"]
}
}
}
A few notes on the analyzers:
- The
minimal_englishstemmer only removes plurals rather than potentially butchering the difference between words like “computer”, “computes”, and “computing”. - Lowercase keyword analyzer makes doing an exact search without case possible.
Let’s take a look at the post mapping:
"post": {
"dynamic_templates": [
{
"tax_template_name": {
"path_match": "taxonomy.*.name",
"mapping": {
"type": "multi_field",
"fields": {
"name": {
"type": "string",
"index": "analyzed",
"analyzer": "wp_analyzer"
},
"raw": {
"type": "string",
"index": "not_analyzed"
},
"raw_lc": {
"type": "string",
"index": "analyzed",
"analyzer": "wp_raw_lowercase_analyzer"
}
}
}
}
}, {
"tax_template_slug": {
"path_match": "taxonomy.*.slug",
"mapping": {
"type": "string",
"index": "not_analyzed"
}
}
}, {
"tax_template_term_id": {
"path_match": "taxonomy.*.term_id",
"mapping": {
"type": "long"
}
}
}
],
"_all": {
"enabled": false
},
"properties": {
"post_id": {
"type": "long"
},
"blog_id": {
"type": "long"
},
"site_id": {
"type": "long"
},
"post_type": {
"type": "string",
"index": "not_analyzed"
},
"lang": {
"type": "string",
"index": "not_analyzed"
},
"url": {
"type": "string",
"index": "not_analyzed"
},
"location": {
"type": "geo_point",
"lat_lon": true
},
"date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd"
},
"date_gmt": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd"
},
"author": {
"type": "multi_field",
"fields": {
"author": {
"type": "string",
"index": "analyzed",
"analyzer": "wp_analyzer"
},
"raw": {
"type": "string",
"index": "not_analyzed"
}
}
},
"author_login": {
"type": "string",
"index": "not_analyzed"
},
"title": {
"type": "string",
"index": "analyzed",
"analyzer": "wp_analyzer"
},
"content": {
"type": "string",
"index": "analyzed",
"analyzer": "wp_analyzer"
},
"tag": {
"type": "object",
"properties": {
"name": {
"type": "multi_field",
"path": "just_name",
"fields": {
"name": {
"type": "string",
"index": "analyzed",
"analyzer": "wp_analyzer",
"index_name": "tag"
},
"raw": {
"type": "string",
"index": "not_analyzed",
"index_name": "tag.raw"
},
"raw_lc": {
"type": "string",
"index": "analyzed",
"analyzer": "wp_raw_lowercase_analyzer",
"index_name": "tag.raw_lc"
}
}
},
"slug": {
"type": "string",
"index": "not_analyzed"
},
"term_id": {
"type": "long"
}
}
},
"category": {
"type": "object",
"properties": {
"name": {
"type": "multi_field",
"path": "just_name",
"fields": {
"name": {
"type": "string",
"index": "analyzed",
"analyzer": "wp_analyzer",
"index_name": "category"
},
"raw": {
"type": "string",
"index": "not_analyzed",
"index_name": "category.raw"
},
"raw_lc": {
"type": "string",
"index": "analyzed",
"analyzer": "wp_raw_lowercase_analyzer",
"index_name": "category.raw_lc"
}
}
},
"slug": {
"type": "string",
"index": "not_analyzed"
},
"term_id": {
"type": "long"
}
}
},
}
}
Most of the fields are pretty self explanatory, so I’ll just outline to more complex ones:
dateanddate_gmt: We define the allowed formats because we are taking the dates out of MySQL. We also do some checking of the dates since MySQL will allow some things in a DATETIME field that ES will balk at and cause the indexing operation to fail. For instance MySQL accepts leap dates in non-leap years.content: Content gets stripped of HTML and shortcodes, then converted to UTF-8 in cases where it isn’t already.authorandauthor.raw: The author field corresponds to the user’s display_name. Clearly we need to analyze the field so “Greg Ichneumon Brown” can be matched on a search for “Greg”, but what about when we facet on the field. If we use the analyzed field then the results would have the terms “greg”, “ichneumon”, and “brown”. Instead, by using ES’s multi_field mapping feature to auto generateauthor.rawthe faceted results on that field will give us “Greg Ichneumon Brown”.tagandcategory: Tags and Categories similarly need raw versions for faceting so we preserve the original tag. Additionally there are a number of ways users can filter the content. WordPress builds slugs from each category/tag to uniquely identify them in a human readable way and there is a unique integer (term_id) associated with each term. Thetag.raw_lcis used for exact matching a term without worrying about the case. This may seem like a lot of duplication, but the overriding goal here is to avoid using MySQL for search so we index everything. Extracting data into multiple fields ensures that we will have flexibility when filtering the data in the future.taxonomy.*: WordPress allows custom taxonomies (of which categories and tags are two built-in taxonomies) so we need a way to create a custom path in each document that allows access to each taxonomy. This is where Elasticsearch’s dynamic templates shine. For a custom taxonomy such as “company” the paths will becometaxonomy.company.name,taxonomy.company.name,taxonomy.company.name.raw,taxonomy.company.slug, andtaxonomy.company.term_id.
The ES documentation is very complete, but it’s not always easy to see how to build complex mappings that fit the individual pieces together. I hope this helps in your own ES development efforts.

Leave a comment